Disks as cache
Outline
Problem statement
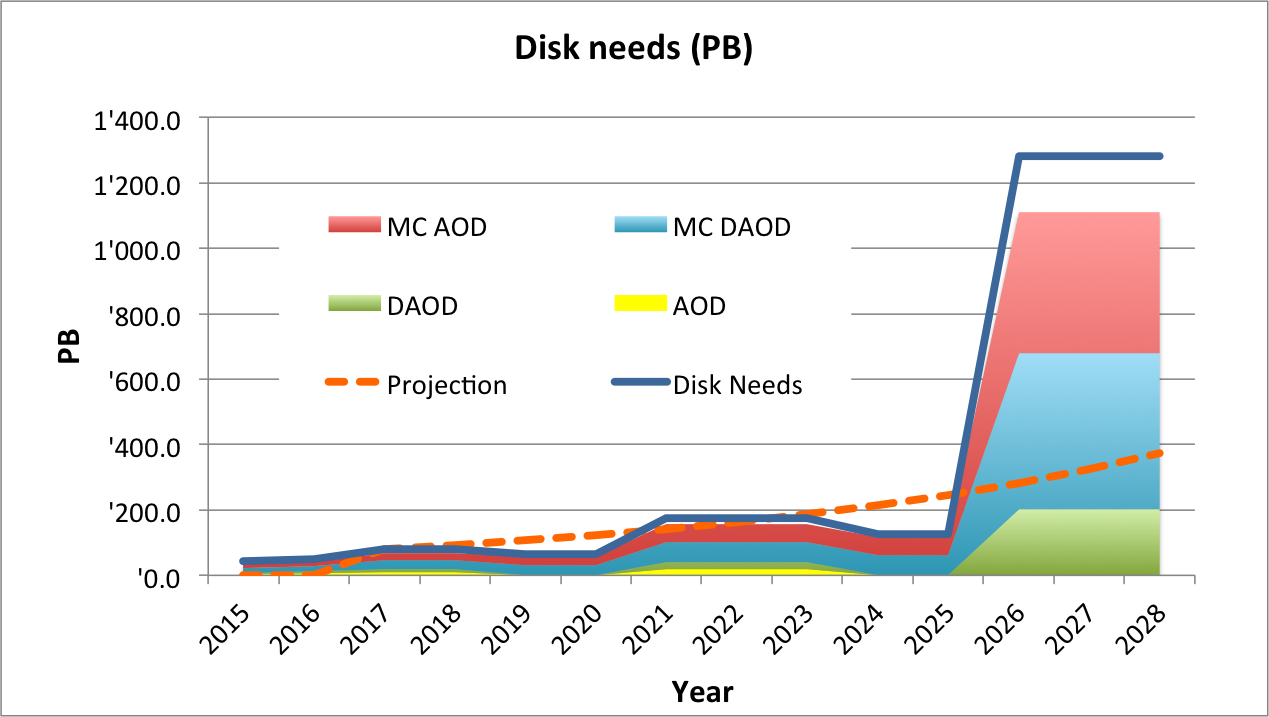
LHC experiments expect to have storage requirements on the order of exabytes once the High Luminosity LHC starts producing data1 2.
With the current scenario of flat budgets, the storage capacity will increase only as much as the technology evolution allows for. This means that by the time the HL-LHC is turned on, the capacity and the needs will be off by a factor of 7.
With a more optimistic scenario this offset is reduced, but still remains at 4 times more capacity needed than available.
At the same time, allowing in smaller sites, or using opportunistic resources (i.e cloud) introduce new maintenance costs.
Proposed solution
Since tapes are still cheaper per byte, custodial responsibilities can be left only for sites with a tape back-end available, since the cost per byte of tape systems is lower than that of disk systems3.
Smaller sites, with disk-only storage, would be left as a cache where data, by definition, is transient.
Additionally, this would also reduce the administrative burden on smaller sites. For instance, resources can be added and removed without concerns about the data, downtimes are not (depending on the approach) be that problematic, etc.
Possible approaches
À la Content Delivery Network
Transparent cache. The user isn’t aware that there is a server close to him/her. A single entry point is known, and it internally decides where and how to populate the data.
À la Squid (proxy server)
The user explicitly request the file to a proxy server that may or may not have the file. The proxy populates the file into its cache.
Difficulties
-
The Grid is formed by an heterogeneous set of sites that are under the control of different entities.
-
ACL have to be honored and enforced by the cache servers.
-
Current X509 authentication and delegation scheme.
-
Only replica available may be on tape, which can have a very big latency.
-
Replication policies may have more to do with event metadata than file names (i.e. a user accessing data to belong to a given run, may be likely to ask shortly for another file of the same dataset).
-
How to replicate efficiently the file if there are more than one existing replica (p2p?).
-
Cache invalidation!
To be checked
There may be an existing xrootd approach4. Looks a lot like this, although they have the typical issue of GSI X509 authentication between servers. The protocol allows for this, though.
On the other hand, it looks like they went for the proxy server approach.