Is `iter != end` faster than `iter < end`?
Yesterday I replaced a condition inside a for loop from iter < end
to iter != end, and I got, surprisingly, a performance improvement.
Oddly, quick-bench.com agreed with me:
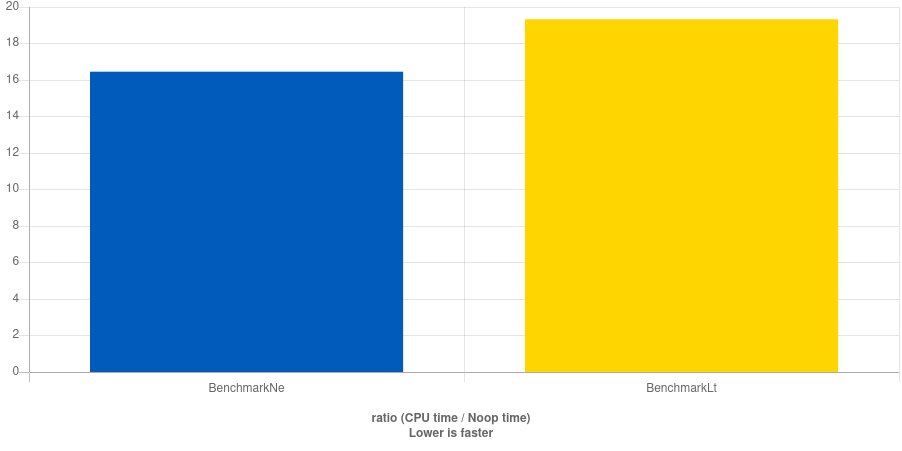
!= is 1.2 times faster than < with gcc 11.2However, there is no difference with clang >=10
gcc seems to add extra instructions for some reason, for instance,
for < just before the loop we get
mov rax, rsi
mov rcx, QWORD PTR [rdi+8]
mov rsi, QWORD PTR [rdi]
mov r8, QWORD PTR [rax]
cmp rsi, rcx
jnb .L7
sub rcx, 1
xor eax, eax
pxor xmm0, xmm0
sub rcx, rsi
shr rcx, 3
With !=
mov rcx, QWORD PTR [rdi]
mov rdx, QWORD PTR [rdi+8]
mov rsi, QWORD PTR [rsi]
cmp rcx, rdx
je .L7
sub rdx, rcx
xor eax, eax
pxor xmm0, xmm0
3 extra instructions: mox rax, rsi, sub rcx, 1 and shr rcx, 3.
As for the loop itself, with <
.L3:
movsd xmm1, QWORD PTR [rsi+rax*8]
subsd xmm1, QWORD PTR [r8+rax*8]
mov rdx, rax
add rax, 1
mulsd xmm1, xmm1
addsd xmm0, xmm1
cmp rcx, rdx
jne .L3
With !=
.L3:
movsd xmm1, QWORD PTR [rcx+rax]
subsd xmm1, QWORD PTR [rsi+rax]
add rax, 8
mulsd xmm1, xmm1
addsd xmm0, xmm1
cmp rdx, rax
jne .L3
An extra mov rdx, rax.
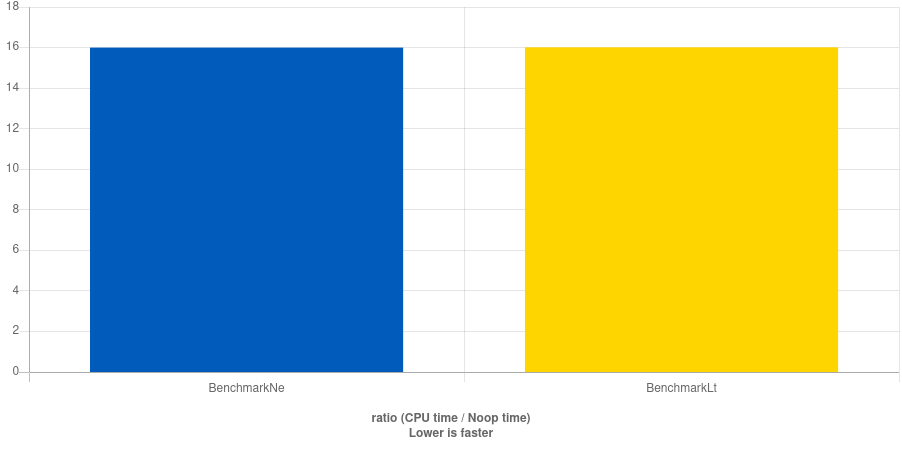
It is worth mentioning that with -O3 there is only one extra instruction
outside the loop, and the difference disappears.